Design For Failure : Comment rendre une application résiliente aux pannes ?

Le Design For Failure (DFF) est la capacité d’un système à résister aux pannes d’autres composants, autrement dit la résilience d’une application.
- Tolérance aux pannes
- Prévention des pannes
- Supervision
Même si on a conçu un système très résilient qui arrive à se réparer tout seul, il est important de savoir s’il s’est passé quelque chose.
Illusions de l’informatique distribuée
| Le réseau est fiable | Le temps de latence est nul | La bande passante est infinie | Le réseau est sûr |
| La topologie du réseau ne change pas | Il y a et un seul administrateur réseau | Le coût de transport est nul | Le réseau est homogène |
Comment fonctionne le Design for failure ?
La loi de Murphy nous dit : tout ce qui est susceptible d’aller mal, ira mal !
Il faut donc se préparer aux erreurs des différents éléments qui composent notre application.
Dans un premier temps, essayer de réparer les erreurs
puis donner une réponse dégradée si besoin
Et ne pas oublier d’informer l’utilisateur.
Les principaux patterns
DFF Côté client
Timeout

Principe bien connu, c’est un de premiers paramètres pour toutes communications distantes (Call HTTP, Read I/O…) : c’est la définition d’un temps d’attente maximal.
Sa durée est à bien définir en fonction du SLA du service interrogé : sur un service d’autocomplétion il doit être ultra-court, mais sur un appel à une base de donnée, il pourra être plus long.
Attention à ne pas oublier de le parametrer car sa valeur par défaut peut nous surprendre :
- en C# le timeout HttpClient par défaut est à 100 secondes ! (docs.microsoft.com)
- en Java / OkHttp, le timeout par défaut est à 0, c’est à dire qu’il attendra indéfiniment (okhttp3)
Retry

Souvent mis en place par défaut dans les applications réseaux (FTP, Message Queues…), il permet de combler à une micro-coupure du réseau.
Bien définir la durée d’attente entre chaque essai et leur nombre
risque de DDos si plusieurs clients se mettent à réessayer continuellement d’appeler un service à l’agonie. Idéalement le délai d’attente sera exponentiel.
Bien définir les causes qui génèrent un nouvel essai
pas de retry pour une erreur de mot de passe !
Attention si la requête n’est pas idempotente
risque de corruption de données
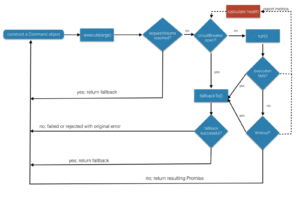
Fallback

Le Plan B : on répond quoi qu’il arrive, soit une réponse normale, soit une réponse dégradée.
Ce qui nous permet d’éviter les erreurs génériques aux utilisateurs.
La réponse dégradée doit être définie avec le métier (message d’erreur contextualisé), il faut informer l’utilisateur qu’il est en mode dégradé.
Notamment pour éviter de mettre en cache une réponse dégradée !
Le Fallback doit être rapide et fiable, prenons l’exemple la résolution DNS d’une URL :
- le cache du navigateur
- le proxy dns du réseau local
- le proxy dns du FAI
- les serveurs racines de l’ICANN
Circuit Breaker

On arrête de s’acharner sur un service qui ne répond pas.
Sur le même principe qu’un disjoncteur électrique, on coupe le circuit,
mais en fonction de règles définies, on va chercher à re-tester périodiquement
la cible pour rétablir le circuit de façon automatique.
Un disjoncteur a 3 états (en informatique au moins) :
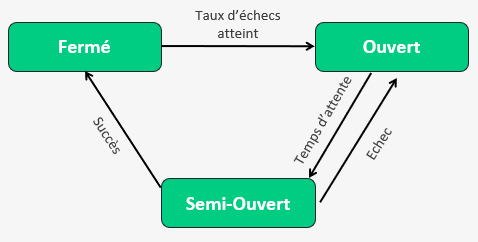
Fermé : tout va bien
les requêtes passent toutes vers leur destination, on alimente l’état de santé du circuit,
jusqu’à ce qu’on atteigne le taux d’échecs et on ouvre le circuit
Ouvert : rien ne vas plus
Toutes les requêtes sont bloquées, on laisse le système cible respirer un peu (il est en PLS), puis une fois le délai d’attente dépassé on passe à l’état suivant
Semi-Ouvert : peut-être que…
On entrouvre le circuit et laissons passer quelques requêtes pour voir comment se comporte le système cible (les ambulanciers sont-ils arrivés ?).
S’il y a toujours des erreurs on repasse à l’état ‘Ouvert’,
mais si les requêtes passent correctement on passe à l’état ‘Fermé’ pour rouvrir les vannes.
Le passage d’un état à l’autre peut-être déclenché de plusieurs façons :
- Nombre d’erreurs / succès basé sur un code de retour
- Nombre d’erreurs / succès basé sur un temps de réponse
- Pourcentage d’erreurs sur une période donnée
- Métrique sur une ressource (% CPU d’une VM)
- Déclenchement manuel (Mise à jour d’une dépendance ?)
=> La supervision est *primordiale* !
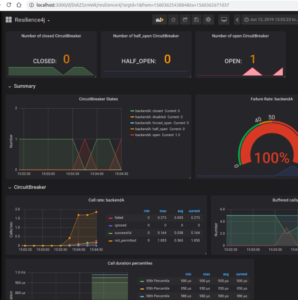
Rien de plus frustrant que de déboguer une application pour comprendre pourquoi un service ne répond pas alors que le circuit est ouvert…
Voici un exemple de monitoring avec Resilience4J
Bulkhead

L’idée c’est d’éviter les effets dominos : une trou dans la coque ne doit pas faire couler le bateau
On parle ici d’isolation de processus à différents niveaux :
- CPU / Thread Pool (Polly / Hystrix / Resilience4J…)
- CPU / Mémoire (WebServer App Pool / Docker…)
- Hôte (VMWare, Kubernetes Pods…)
- Ressources physiques (Cluster, DataCenter, Cloud…)
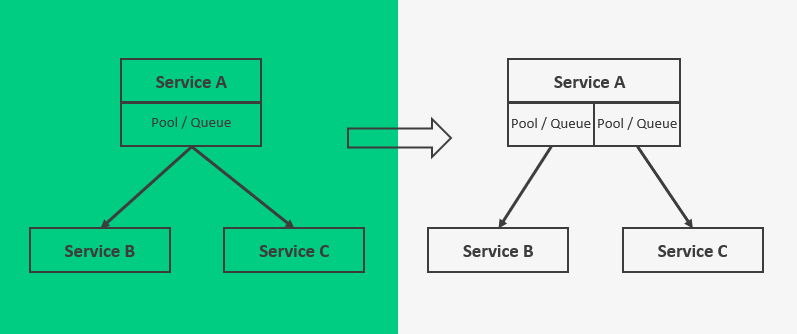
Dans le schéma ci-contre, si le service B vient à ralentir voire ne plus accepter de requêtes, on peut isoler les processus d’envoi pour ne pas pénaliser les requêtes au service C.
BackPressure & Rate Limiter
L’empathie entre services

Il s’agit ici de limiter les appels à une ressource, et même de garder un visu sur la santé de cette ressource.
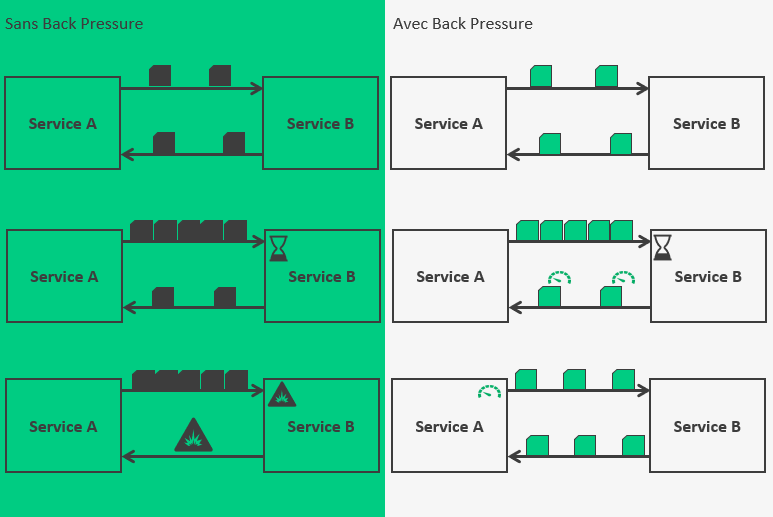
Sans BackPressure, lorsqu’il y a peu d’appels, tout va bien,
mais lorsque la charge augmente, et que le service cible n’arrive pas à dépiler sa pile de requête assez rapidement, il va surcharger, puis il risque de partir en erreur.
Avec BackPressure, la réponse du service cible est contenue dans une enveloppe qui décrit la santé du service. Si la charge devient trop élevée, le service cible pourra signaler un ralentissement dans son traitement, et le service demandeur devra limiter ses requêtes (le rate limiter).
Les Frameworks
Java
Hystrix (NetFlix)
Premier framework de résilience (en Java), rendu open-source, mais ensuite délaissé (fin 2018) par NetFlix
https://github.com/Netflix/Hystrix

Resilience4J
Librairie Java inspirée d’Hystrix, mais implémentée en suivant les préceptes de la programmation fonctionnelle.
https://github.com/resilience4j/resilience4j
Javascript
HystrixJS
Portage d’Hystrix en Javascript
https://www.npmjs.com/package/hystrixjs
Simplified-hystrixjs
https://github.com/julekgwa/simplified-hystrixjs
Brakes
.NET
Hystrix.NET
Portage d’Hystrix en .NET
https://github.com/Travix-International/Hystrix.Dotnet
Polly
Librairie inspirée d’Hystrix, mais dotnet native
http://www.thepollyproject.org/
et accessoirement mise en avant par Microsoft (docs.microsoft.com)
API Gateway & Service Mesh
DFF Côté service
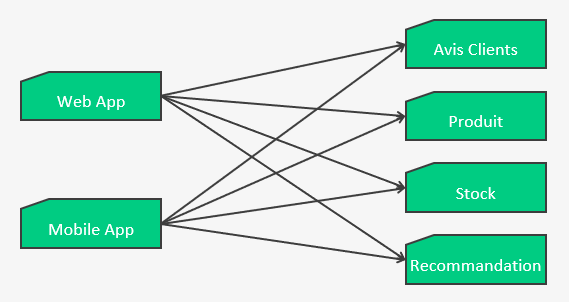
Jusqu’à maintenant on a parlé de comment protéger des appels vers des services externes. Il faudrait donc répéter/réutiliser/dupliquer les stratégies de DFF pour chaque services distants, comme dans le schéma suivant :
C’est là qu’interviennent les principes d’API Gateway, de BackForFront et de Service Mesh
API Gateway
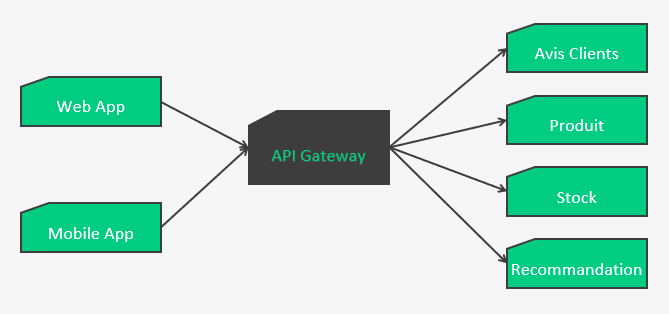
L’API Gateway va servir de proxy et centralisation pour protéger les services distants.
Et là vous me rétorquerez qu’on a juste déplacé le problème ! Oui et non, car maintenant on peut s’appuyer sur d’autres plateformes pour gérer l’API Gateway. Cette brique n’as pas besoin d’être développée et maintenue en interne, on peut utiliser celles qui sont sur le marché et ainsi ne gérer que de la configuration, telles que (liste non exhaustive) :
De plus, ça va limiter les échanges réseaux entre les apps et les services distants. D’un côté ça augmente la sécurité (les services distants n’ont plus à être visible depuis internet, et en terme de flux réseaux on sait exactement lesquels doivent rester ouverts et être sécurisés), de l’autre ça réduit la quantité de données transitant entre l’application et les services distants (merci les forfaits Data des téléphones).
Back For Front
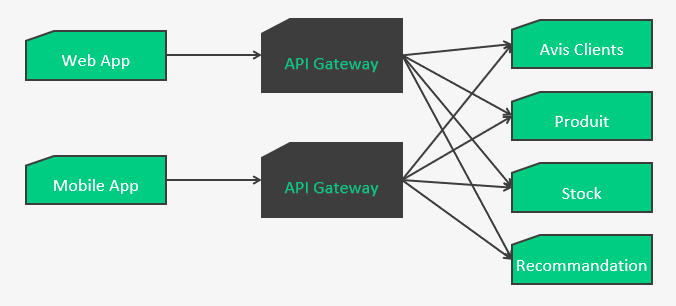
Les BestFriendForever BFF sont une variante de l’API Gateway, où une gateway va se spécialiser et se dédier à une application front.
Service Mesh
Et maintenant comment ça se passe dans une galaxie de microservices ?
Dans le cas où un service doit en appeler d’autres ?
Potentiellement on peut arriver sur ce genre de résultat :
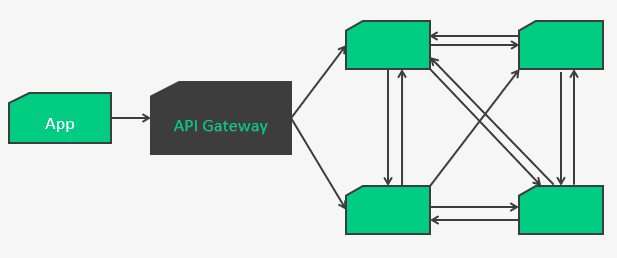
La complexité de gestion d’incident, de discovery, de load-balancing grimpe de façon exponentielle et quid des mises à jour ? Autant de code de gestion technique qui vient polluer le code métier.
C’est là qu’interviennent les service meshs avec le pattern de sidecar proxy.
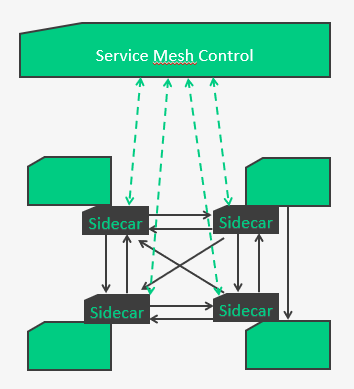
Les services ont tous un sidecar proxy associé par lequel passeront toutes les communications réseaux. C’est donc eux qui viendront s’identifier sur le control, qui s’occuperont de toute la remontée de stats (pour l’état des disjoncteur par ex), qui géreront toute la complexité des échanges services à services.
A partir du control, on pourra avoir un suivi en temps réel des communications,
gérer les flux (rate limiter par ex)…
Voici une liste non-exhaustive des solutions de service mesh sur le marché
En quelques mots un service mesh permet de :
- simplifier l’interconnexion des services
- sécuriser les services (autorisation, identification, chiffrement des échanges)
- contrôler les flux
- surveiller l’état des communications
Pour conclure
Comme tous les patterns, ceux présentés ici sont à utiliser à bon escient,
et avec le bon framework leur mise en place peut-être facile.
Il faut toujours valider avec le métier les paramètres du DFF et le mode dégradé.
Il ne faut surtout pas sous-estimer :
- Les tests et tuning des paramètres
- La supervision
Pour aller plus loin :
- Design For Failure au niveau Infra (Autoscaling Group…)
- Chaos Engineering : http://principlesofchaos.org
Principe né chez Netflix, l’idée c’est de tester en PROD la perte d’une application/serveur/datacenter, et ils ont donc développé tout un tas d’outils qui viennent perturber leur environnement de production : Chaos Monkey (qui détruit des VMs) et toute la suite Simian Army
Références
La résilience chez Netflix
https://netflixtechblog.com/making-the-netflix-api-more-resilient-a8ec62159c2d
Resilience4J Graphana dashboard
https://dev.to/silviobuss/resilience-for-java-microservices-circuit-breaker-with-resilience4j-5c81
Le chaos engineering à la SNCF
https://www.lemagit.fr/actualites/450430813/Chaos-Engineering-ou-le-stress-ultime-des-applications-et-de-linfrastructure-et-utilise-par-OUISN
https://ouitalk.oui.sncf/article/focus/tout-en-ordre-lingenierie-du-chaos-chez-ouisncf
L’excellent article d’Objectif Libre
https://www.objectif-libre.com/fr/blog/2019/09/05/service-mesh-decouverte-et-mise-en-oeuvre
Service Mesh Guide
https://www.infoq.com/articles/service-mesh-ultimate-guide
Merci à Antonio Gomes Rodrigues
