L'orchestration de containers : quelles alternatives à Kubernetes ?

Chez Cantor, nous utilisons la technologie Docker depuis ses débuts.
Nous sommes très grands consommateurs de celle-ci, au point de « dockeriser » chacune de nos applications tant que possible.
En association avec Docker, nous utilisons également Ansible pour automatiser et centraliser le déploiement de nos applications depuis maintenant quelques années.
De ce fait, nous possédons à ce jour plusieurs centaines de conteneurs d’applications aussi bien pour des environnements de sandbox, de recette mais aussi de production.
C’est donc tout naturellement que nous nous sommes posés la question des technologies d’ orchestration de ces conteneurs.
Cette question est d’actualités lorsque l’on évoque la question d’un plan de reprise d’activité (PRA), renforcée en cette période de confinement.
Quelle est le rôle d’un orchestrateur de containers ?
Aujourd’hui les applications ne sont plus monolithiques.
Elles sont au contraire composées de multiples composants mis en conteneurs associés qui doivent fonctionner ensemble.
L’orchestration de containers permet avant tout d’organiser un flux de travail des composants individuels et du niveau des applications.
A partir du processus d’organisation de travail, Les outils d’orchestration de containers permettent aux utilisateurs de guider le déploiement de conteneur et d’automatiser les mises à jour, la surveillance d’état et les procédures de basculement.
Docker et Kubernetes VS Swarm : Évaluation dans le contexte de Cantor
Il y a plusieurs mois, nous avons réalisé une première étude pour évaluer Kubernetes dans notre contexte.
Notre étude nous a démontré qu’il existe bien des alternatives plus adaptés que l’utilisation de Kubernetes. Nous avons donc étudié l’hypothèse d’une orchestration de containers plus pragmatique et simple à intégrer : Swarm.
Pour Cantor, l’orchestration de containers ont des objectifs particuliers :
- Des déploiements et mises à jour simples
- Une meilleure gestion des ressources
- Des services résilients
- Une scalabilité
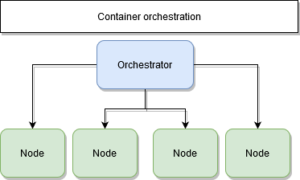
Le contexte d'usage
- Un ensemble de nœuds prêts à l’emploi
- Un (ou plusieurs) manager
- Un (ou plusieurs) worker
- Un moteur de conteneur : Docker
- Un moteur d’orchestration : Swarm
Contexte d’usage d’un container d’orchestration
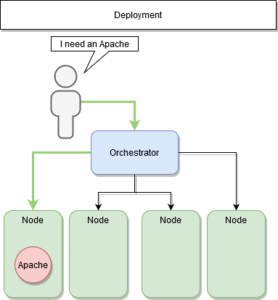
Le (re)déploiement
Dans une architecture orchestrée, nous communiquons uniquement avec nos managers.
Nous leur demandons de déployer nos services, indépendamment de leurs localisations. Le manager définit sur quelle machine le déployer et chaque nœud susceptible de l’héberger.
Déploiement
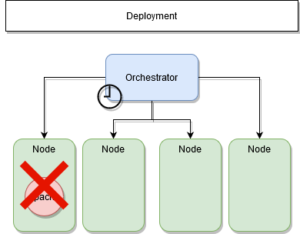
Que se passe-t-il lorsqu’un nœud est hors service ?
Dans achitecture technique comme celle-ci, le rôle des managers est de conserver l’état initial.Cet état initial est définit par les services déployés avec leurs nombres de réplicas. Lorsqu’un nœud est hors service, le manager est averti dans un délai très court.
Il va donc redéployer les services qui étaient présents sur les autres nœuds du système.
ETAPE 1 : Nœud hors service
ETAPE 2 : Redéploiment
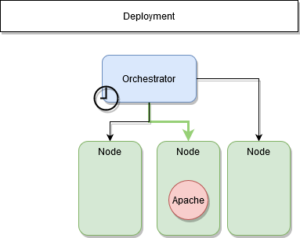
Le service est-il interrompu ?
La scalabilité : déployer plusieurs instances d’un même service
La scalabilité
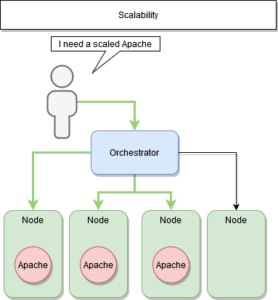
La « scalabilité » est le fait de déployer plusieurs instances d’un même service.
Il y a deux avantages majeurs à la sacalabilité :
- La continuité de service
- La répartition de charge
La continuité de service est assuré par le manager qui conserve son état initial compte-tenu de ses nœuds à disposition.
C’est également lui qui s’occupe de la répartition de charge ou load balancing entre les différents couple nœud-service.
ETAPE 1 : Nœud hors service
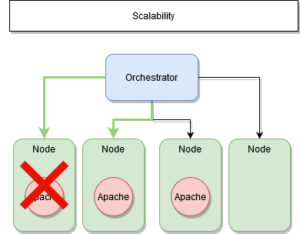
ETAPE 2 : Préserver l’état initial
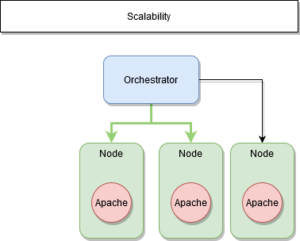
Le manager connaît donc en temps réels les états de ses nœuds et services.
Cela fonctionne parfaitement pour des services « stateless ».
Qu’en est-il des services « stateful » ?
Effectivement, dans ce type d’architecture, le service ou le programme peut être déployé n’importe où sur le système, mais il est indispensable de l’associer aux données qui lui sont propres.
En effet, le programme doit enregistrer les données clients des activités d’une session pour une utilisation dans la session suivante.
ETAPES 3 : Services stateful
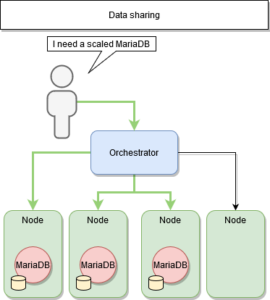
Le partage de données
La solution intuitive est donc de partager les données entre les différents services déployés.
Nativement, Docker propose des volumes pour persister la donnée des conteneurs, cependant Swarm ne gère pas ce partage entre les différents nœuds.
- L’utilisation de services prévus à cet effet
- L’utilisation de solutions externes de mutualisation des volumes
Dans notre premier cas, cela revient à modifier la façon dont sont conçus nos services, dans le cas d’une base de données, Redis est un bon candidat.
Encore faut-il savoir l’intégrer 🙂
Dans notre deuxième cas, il s’agit de plugins Docker.
Ce plugin modifie la façon dont sont gérés les volumes, en étant transverse.
L’idée est d’accéder aux données à travers une API, afin d’obtenir la même source d’information peu importe le nœud.
REX-Ray ou BlockBridge le proposent.
Dans cette deuxième solution, le point d’accès aux données devient à nouveau un maillon faible : S’il est hors service, tous nos nœuds le sont également.
Supposons conserver un cache localement, lequel de nos services possède l’information correcte après plusieurs requêtes de modifications ?
La réponse est intuitive 🙂
Plugin docker
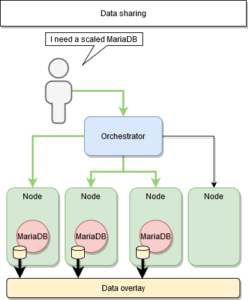
Alors dans quelles mesures peut-on répliquer ce service transverse ?
La question reste ouverte !
